

There’s been some Friday night kernel drama on the Linux kernel mailing list… Linus Torvalds has expressed regrets for merging the Bcachefs file-system and an ensuing back-and-forth between the file-system maintainer.
Kent developed for like 10 years on his own. He’s just having a hard time learning how to play with others, and deal with large priority cycles. He just needs to know that sometime his changes will get pushed to the next cycle.
This. Well said.
Kent is reasonable, and sees Linus’s need to keep order. I think he just pushes it sometimes, and doesn’t understand how problematic that can be.
That said - he has resubmitted an amended version of the patch, that doesn’t touch code outside of bcachefs, and is less than 1/3 the size.
Can someone say why bcachefs is interesting? Btrfs I can sort of understand. I haven’t much kept track of most others.
bcachefs is way more flexible than btrfs on multi-device filesystems. You can group storage devices together based on performance/capacity/whatever else, and then do funky things like assigning a group of SSDs as a write-through/write-back cache for a bigger array of HDDs. You can also configure a ton of properties for individual files or directories, including the cache+main storage group, amount of data replicas, compression type, and quite a bit more.
So you could have two files in the same folder, one of them stored compressed on an array of HDDs in RAID10 and the other one stored on a different array of HDDs uncompressed in RAID5 with a write-back SSD cache, and wouldn’t have to fiddle around with multiple filesystems and bind mounts - everything can be configured by simply setting xattr values. You could even have a third file which is striped across both groups of HDDs without having to partition them up.
Thank you. w o w
two files in the same folder, one of them stored compressed on an array of HDDs in RAID10 and the other one stored on a different array […]
Now that’s what I call serious over-engineering.
Who in the world wants to use that?
And does that developer maybe have some spare time? /s
This is actually a feature that enterprise SAN solutions have had for a while, being able choose your level of redundancy & performance at a file level is extremely useful for minimising downtime and not replicating ephemeral data.
Most filesystem features are not for the average user who has their data replicated in a cloud service; they’re for businesses where this flexibility saves a lot of money.
Simple example: my Steam library could be RAID0 and unencrypted but my backups I definitely want to be RAID1 and compressed, and encrypted for security. The media library doesn’t need encryption but maybe want it in RAID1 because ripping movies takes forever. I may also want to have the games on NVMe when I play them, and stored on the HDDs when I’m not playing them, and my VMs on the SATA SSD array as a performance middleground.
Steam library
backups
media library
Wonderful.
But these are libraries. Not single files.
This probably meets some extreme corporate usecase where they are serving millions of customers.
It’s not that obscure - I had a use case a while back where I had multiple rocksdb instances running on the same machine and wanted each of them to store their WAL only on SSD storage with compression and have the main tables be stored uncompressed on an HDD array with write-through SSD cache (ideally using the same set of SSDs for cost). I eventually did it, but it required partitioning the SSDs in half, using one half for a bcache (not bcachefs) in front of the HDDs and then using the other half of the SSDs to create a compressed filesystem which I then created subdirectories on and bind mounted each into the corresponding rocksdb database.
Yes, it works, but it’s also ugly as sin and the SSD allocation between the cache and the WAL storage is also fixed (I’d like to use as much space as possible for caching). This would be just a few simple commands using bcachefs, and would also be completely transparent once configured (no messing around with dozens of fstab entries or bind mounts).
Is there a reason for bind mounting and not just configuring the db to point at a different path?
I mean… If you have a ton of raw photos in one directory, you can enable the highest compression rate with zstd to it. Every other directory has lz4 with the fastest compression. Your pics take much less space, but the directory will be slower to read and write.
My company serves millions, too. We don’t have such needs.
Congrats.
Sounds like zfs with extra steps
But is GPL-compatible, unlike ZFS.
How do you define GPL compatible?
Do your own research, that’s a pretty well-discussed topic.
I’m all over ZFS and I am not aware of any unresolved “licence issues”. It’s like a decade old at this point
Your lack of awareness is fine with me.
ZFS doesn’t support tiered storage at all. Bcachefs is capable of promoting and demoting files to faster but smaller or slower but larger storage. It’s not just a cache. On ZFS the only option is really multiple zpools. Like you can sort of do that with the persistent L2ARC now but TBs of L2ARC is super wasteful and your data has to fully fit the pool.
Tiered storage is great for VMs and games and other large files. Play a game, promote to NVMe for fast loadings. Done playing, it gets moved to the HDDs.
You’re misrepresenting L2ARC and it’s a silly comparison to claim to need TBs of L2ARC and then also say you’d copy the game to nvme just to play it on bcachefs. That’s what ARC does. RAM and SSD caching of the data in use with tiered heuristics.
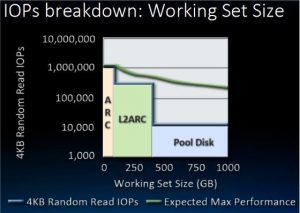
I know, that was an example of why it doesn’t work on ZFS. That would be the closest you can get with regular ZFS, and as we both pointed out, it makes no sense, it doesn’t work. The L2ARC is a cache, you can’t store files in it.
The whole point of bcachefs is tiering. You can give it a 4TB NVMe, a 4TB SATA SSD and a 8 GB HDD and get almost the whole 16 TB of usable space in one big filesystem. It’ll shuffle the files around for you to keep the hot data set on the fastest drive. You can pin the data to the storage medium that matches the performance needs of the workload. The roadmap claims they want to analyze usage pattern and automatically store the files on the slowest drive that doesn’t bottleneck the workload. The point is, unlike regular bcache or the ZFS ARC, it’s not just a cache, it’s also storage space available to the user.
You wouldn’t copy the game to another drive yourself directly. You’d request the filesystem to promote it to the fast drive. It’s all the same filesystem, completely transparent.
Looks dead on arrival to me, so much complexity for “performance” but the filessystem is outclassed by everything else in existence. If there was any real performance from this complexity it could have cool niche use cases but this is very disappointing https://www.phoronix.com/review/bcachefs-linux-67/2
For me the reason was that I wanted encryption, raid1 and compression with a mainlined filesystem to my workstation. Btrfs doesn’t have encryption, so you need to do it with luks to an mdadm raid, and build btrfs on top of that. Luks on mdadm raid is known to be slow, and in general not a great idea.
ZFS has raid levels, encryption and compression, but doesn’t have fsck. So you better have an UPS for your workstation for electric outages. If you do not unmount a ZFS volume cleanly, there’s a risk of data loss. ZFS also has a weird license, so you will never get it with mainline Linux kernel. And if you install the module separately, you’re not able to update to the latest kernel before ZFS supports it.
Bcachefs has all of this. And it’s supposed to be faster than ZFS and btrfs. In a few years it can really be the golden Linux filesystem recommended for everybody. I sure hope Kent gets some more help and stops picking fights with Linus before that.
ZFS doesn’t have fsck because it already does the equivalent during import, reads and scrubs. Since it’s CoW and transaction based, it can rollback to a good state after power loss. So not only does it automatically check and fix things, it’s less likely to have a problem from power loss in the first place. I’ve used it on a home NAS for 10 years, survived many power outages without a UPS. Of course things can go terribly wrong and you end up with an unrecoverable dataset, and a UPS isn’t a bad idea for any computer if you want reliability.
Totally agree about mainline kernel inclusion, just makes everything easier and ZFS will always be a weird add-on in Linux.
Btrfs doesn’t have encryption, so you need to do it with luks to an mdadm raid, and build btrfs on top of that. Luks on mdadm raid is known to be slow, and in general not a great idea.
Why involve mdadm? You can use one btrfs filesystem on a pair of luks volumes with btrfs’s “raid1” (or dup) profile. Both volumes can decrypt with the same key.
Bcachefs has all of this. And it’s supposed to be faster than ZFS and btrfs. In a few years it can really be the golden Linux filesystem recommended for everybody
ngl, the number of mainline Linux filesystems I’ve heard this about. ext2, ext3, btrfs, reiserfs, …
tbh I don’t even know why I should care. I understand all the features you mentioned and why they would be good, but i don’t have them today, and I’m fine. Any problem extant in the current filesystems is a problem I’ve already solved, or I wouldn’t be using Linux. Maybe someday, the filesystem will make new installations 10% better, but rn I don’t care.
It’s a filesystem that supports all of these features (and in combination):
- snapshotting
- error correction
- per-file or per-directory “transparently compress this”
- per-file of per-directory “transparently back this up”
If that is meaningless to you, that’s fine, but it sure as hell looks good to me. You can just stick with ext3 - it’s rock solid.
Encryption and compression don’t play well together though. You should consider that when storing sensitive files. That’s why it’s recommended to leave compression off in https because it weakens the encryption strength
How does that work? Encryption should not care at all about the data that is being encrypted. It is all just bytes at the end of the day, should not matter if they are compressed or not.
Disabling compression in HTTPS is advised to prevent specific attacks, but this is not about compression weakening encryption directly. Instead, it’s about preventing scenarios where compression could be exploited to compromise security. The compression attack is used to leak information about the content of the encrypted data, and is specific to HTTP, probably because HTTP has a fixed or guessable structure.
Looks to be an exploit only possible because compression changes the length of the response and the data can be injected into the request and is reflected in the response. So an attacker can guess the secret byte by byte by observing a shorter response form the server.
That seems like something not feasible to do to a storage device or anything that is encrypted at rest as it requires a server actively encrypting data the attacker has given it.
We should be careful of seeing a problem in one very specific place and then trying to apply the same logic to everything broadly.
It is only in TLS where you have to disable compression, not in HTTP.
https://security.stackexchange.com/questions/19911/crime-how-to-beat-the-beast-successor/19914#19914
Could you explain how a CRIME attack can be done to a disk?
bcachefs is meant to be more reliable than btrfs - which has had issues with since it was released (especially in the early days). Though bcachefs has yet to be proven at scale that it can beat btrfs at that.
Bcachefs also supports more features I believe - like encryption. No need for an extra layer below the filesystem to get the benefits of encryption. Much like compression that also happens on both btrfs and bcachefs.
Btrfs also has issues with certain raid configurations, I don’t think it yet has support for raid 5/6 like setup and it has promised that for - um, well maybe a decade already? and I still have not heard any signs of it making any progress on that front. Though bcachefs also still has this on their wishlist - but I see more hope for them getting it before btrfs which seems to have given up on that feature.
Bcachefs also claims to have a cleaner codebase than btrfs.
Though bcachefs is still very new so we will see how true some of its claims will end up being. But if true it does seem like the more interesting filesystem overall.
Also because it’s meant to be an enterprise level filesystem like ZFS, but without the licensing baggage. They share a lot of feature sets.
In addition to the comment on the mentioned better hardware flexibility, I’ve seen really interesting features like defining compression & deduplication in a granular way, even to the point of having a compression algo when you first write data, and then a different more expensive one when your computer is idle.
deleted by creator
Bruh, you can’t just submit entirely new data structures as “fixes”, let alone past the merge window.
It should not be hard at all to grasp that.
He accepted Linus’s needs as the project head to keep order. He resubmitted the patch set without the contentious parts. It’s less than 1/3 the size and doesn’t touch code outside of bcachefs. Problem solved.
Honestly, Kent seems pretty reasonable (though impassioned), and bcachefs well probably make it, and Kent will get used to just submitting things at the right time in the cycle.
I was interested in bcachefs years ago, but Kent seems to keep shooting himself in the foot when it comes to getting any traction with it.
It’s not as bad as it seems. He just doesn’t know how valuable working with the provided structure is yet. A lot of innovative thinkers are used to questioning, bending, and tinkering with the rules. He’s just still learning how necessary the existing structure is.
I’m going to switch from BTRFS at some point, but at this point that’s going to be a few years down the line.
Btrfs never really worked out for me (I think default COW doesn’t play nice with VM images) and ext4 works great.
You can disable COW for specific files btw
gods, imagine saying this to a normal user
“what the fuck is a file?”
Normal users don’t have VM images…
Gnome boxes and libvirt do it automatically for their VM directories… it works and a normal user doesn’t have to know a bunch.
Ext4 is faster, but I love BTRFS not just because of CoW, but subvolumes as well. You could probably get something similar going with LVFS, but I prefer that to be baked in, hence why I’m waiting for bcachefs, because it’ll up the ante with tighter integration, so that might translate to better performance.
Notice my use of the word might. BTRFS performance is not so great.
Ext4 on personal computer and ZFS on my server
I’d consider btrfs if they finally make their raid5/6 implementation stable. I want to work with multiple disks without sacrificing half of my storage.
I definitely feel bcachefs is much more practical than zfs for home storage, I’ve used both. I don’t use zfs unless it’s TrueNAS because of the licensing issues, but bcachefs solves all of that and you can use different sized drives. I look forward to it being stable and glad it’s working out. Luckily the only side affect is Linus’ regretfulness. 😂
Was considering bcachefs at some point but after seeing this, definitely a no for the foreseeable future. I don’t like surprises in my file systems.
Use ext4. It just works.
ext4 is intended for a completely different use case, though? bcachefs is competing with btrfs and ZFS in big storage arrays spanning multiple drives, probably with SSD cache. ext4 is a nice filesystem for client devices, but doesn’t support some things which are kinda fundamental at larger scales like data checksumming, snapshots, or transparent compression.
There’s XFS for larger scale stuff.
XFS still isn’t a multi-device filesystem, though… of course you can run it on top of mdraid/LVM, but that still doesn’t come close to the flexibility of what these specialized filesystems can do. Being able to simply run
btrfs device add /dev/sdx1 /and immediately having the new space available is far less hassle than adding a device to an md array, then resizing the partition and then resizing the filesystem (and removing a device is even worse). Snapshots are a similar deal - sure, LVM can let you snapshot your entire virtual block device, but your snapshots are block devices themselves which need to be explicitly mounted, while in btrfs/bcachefs a snapshot is just a directory, and can be isolated to a specific subvolume rather than the entire block device.Data checksums are also substantially less useful when the filesystem can’t address the underlying devices individually, because it makes repairing the data from a replica impossible. If you have a file on an md RAID1 device and one of the replicas has a bad block, you might be able to detect the bitrot by verifying the checksum, but you can’t actually fix it, because even though there is a second copy of the data on another drive, mdadm simply exposes a simple block device and doesn’t provide any way to read from “the other copy”. mdraid can recover from total drive failure, but not data corruption.
Is XFS still maintained?
One of the best filesystem codebases out there. Really a top notch file system if you don’t need to resize it once it’s created. It is a write through, not copy on write, so some features such as snapshots are not possible using XFS. If you don’t care about features found in btrfs, zfs or bcachefs, and you don’t need to resize the partition after creating it, XFS is a solid and very fast choice.
Ext4 codebase is known to be very complex and some people say even scary. It just works because everybody’s using it and bugs have been fixed years ago.
Ext4 codebase is known to be very complex and some people say even scary. It just works because everybody’s using it and bugs have been fixed years ago.
I heard that ext4s best feature was its fsck utils being extremely robust and able to recover from a lot of problems. Which does not shine a great light on the filesystem itself :/ and probably a result of the complex codebase.
if you don’t need to resize it once it’s created
xfs_growfs is a thing. I know nothing about xfs. Is this something I should avoid for some reason?
No reason to avoid it. Just know that you can’t easily shink the filesystem, only grow it. To shrink you’d need to create a new FS then copy the data over manually.
It’s used in RHEL.
Honestly I’m fine with ZFS on larger scale, but on desktop I want a filesystem that can do compassion (like NTFS on windows) and snapshots.
I have actually used compression a lot, and it spared me a lot of space. No, srorage is not cheap, or else I’m awaiting your shipment.
Other than that I’m doing differential backups on windows, and from time to time it’s very useful that I can grab a file to which something just happened. Snapshots cost much less storage than complete copies, which I couldn’t afford, but this way I have daily diffs for a few years back, and it only costs a TB or so.
You might as well say use fat32 it just works.
FAT32 does not just work for my Linux OS.
To people who just want to browse the web, use Office applications and a few other things, ext4 just works and FAT32 really just doesn’t.
I get the point you’re trying to make, FAT32 also has a small file size and is missing some features, ext4 is like that to for instance Bcachefs.
But FAT32 (and exFAT and a few others) have a completely different use cases; I couldn’t use FAT32 for Linux and expect it to work, I also couldn’t use ext4 for my USB stick and expect it to just work as a USB stick.Not really. It has a quite small file size limit afaik.
Like there’s not a bunch of stuff EXT 4 can’t do that BTRFS and whatever this other acronym soup can do.
It’s the entire point of my post. E x t 4 does work but it doesn’t do the stuff these other file systems do so they are an advantageous choice for some things.
One point: ext4 has a maximum file size of 16TiB. To a regular user that is stupidly huge and of no concern but it’s exactly the type of thing you overlook if you “just use ext4” on anything and everything then end up with your database broken at work because of said bad advice.
Use the filesystem that makes the most sense for your use case. Consider it every single time you format a disk. Don’t become complacent! Also fuck around with the new shit from time to time! I decided to format my Linux desktop partitions with btrfs over a decade ago and as a result I’m an excellent user of that filesystem but you know what? I’m thinking I’ll try bcachefs soon and fiddle around more with my zfs partition on my HTPC.
BTW: If you’re thinking about trying out btrfs I would encourage you to learn about it’s non-trivial maintenance tasks. btrfs needs you to fuck with it from time to time or you’ll run out of disk space “for no reason”. You can schedule cron jobs to take care of everything (as I have done) but you still need to learn how it all works. It’s not a “set it and forget it” FS like ext4.
For a few years I used a distro that had btrfs as default, including scheduled automatic maintenance. Never had to bother about manual balancing or fiddeling with the FS.
I have 52 terabytes of BTRFS, I’ve been on it for about 5 years.
I think we’re just talking about different priorities. For me stability is the most important in production. For you features seem to matter more. For me it’s enough if a file system can store, write, read and not lose files. I guess it depends on what the use case and the budget are.
Yeah, some people have needs that you don’t have. That’s why I commented on your blanket statement of just use EXT4.
I have BTRFS in production all over the place. Snapshots are extremely useful for what I do.
and not lose files
Which is exactly why you’d want to run a CoW filesystem with redundancy.
ext4 aims to not lose data under the assumption that the single underlying drive is reliable. btrfs/bcachefs/ZFS assume that one/many of the perhaps dozens of underlying drives could fail entirely or start returning garbage at any time, and try to ensure that the bad drive can be kicked out and replaced without losing any data or interrupting the system. They’re both aiming for stability, but stability requirements are much different at scale than a “dumb” filesystem can offer, because once you have enough drives one of them WILL fail and ext4 cannot save you in that situation.
Complaining that datacenter-grade filesystems are unreliable when using them in your home computer is like removing all but one of the engines from a 747 and then complaining that it’s prone to crashing. Of course it is, because it was designed under the assumption that there would be redundancy.
Well, yes use-case is key. But interestingly ext4 will never detect bitrot/errors/corruption. BTRFS will detect corrupted files because its targeted users wants to know. It makes it difficult to say what’s the more reliable FS because first we’d have to define “reliable” and the perception of it and who/what do we blame when the FS tells us there’s a corrupted file detected?. Do we shoot the messenger?
FAT32 goes up to 2TB. 16TB if you increase the sector size beyond what Windows supports. The only limit you may run into is the 256GiB file size limit. For most installs, it does indeed just work.
It also does not support unix file permissions - so for most installs it does indeed not work.
No. You can layer ext4 with LVM and LUKS to get a lot of features (but not all) that you get with BTRFS or ZFS. FAT is not suitable for anything other than legacy stuff.
My point is there are features that you don’t get in EXT that are completely reasonable to use and workflows.
When someone says just use EXT4, they’re just missing the fact that people may want or need those other features.
Your response to FAT is exactly my point.
Torvalds rejected the merge, and that’s pretty much what he said - no one is using bcachefs.
There’s no reason for a “fix” to be 1k+ lines, these sorts of changes need to come earlier in the release cycle.
The article is not about which filesystem to use or not, but about the size and contents of the patches submitted in relation to bcachefs. It seems that the submitted changes which should have been just fixes also contain new functionality. Though it is very nice to see how active and enthusiastic the development of bcachefs is, mixing fixes with new functionality is hard to review and dangerous as it can introduce additional issues. Again, while I appreciate Kents work, I understand Linus’ concerns.
Red Hat recommends XFS by default. That’s probably the most “it just works” filesystem out there. Slightly faster than ext4, too!
I once had the whole FS corrupted and I don’t remember if it was XFS or ZFS (probably the latter). Also I like messing around with interesting software that might not support less common filesystems so I just stick with ext4. XFS is great though.
XFS is 24 years old, six years older than the first merged version of ext4. It’s the standard for enterprise Linux deployments. This isn’t some small indie filesystem like BTRFS or F2FS. It also doesn’t do any of the complicated stuff BTRFS and ZFS do to bring filesystems into the 21st century, so repairing it is much easier.
I wouldn’t say, “repairing XFS is much easier.” Yeah,
fsck -ywith XFS is really all you have to do 99% of the time but also you’re much more likely to get corrupted stuff when you’re in that situation compared to say, btrfs which supports snapshotting and redundancy.Another problem with XFS is its lack of flexibility. By that I don’t mean, “you can configure it across any number of partitions on-the-fly in any number of (extreme) ways” (like you can with btrfs and zfs). I mean it doesn’t have very many options as to how it should deal with things like inodes (e.g. tail allocation). You can increase the total amount of space allowed for inode allocation but only when you create the filesystem and even then it has a (kind of absurdly) limited number that would surprise most folks here.
As an example, with an XFS filesystem, in order to store 2 billion symlimks (each one takes an inode) you would need 1TiB of storage just for the inodes. Contrast that with something like btrfs with
max_inlineset to 2048 (the default) and 2 billion symlimks will take up a little less than 1GB (assuming a simplistic setup on at least a 50GB single partition).Learn more about btrfs inlining: https://btrfs.readthedocs.io/en/latest/Inline-files.html
deleted by creator
You had corruption with btrfs? Was this with a spinning disk or an SSD?
I’ve been using btrfs for over a decade on several filesystems/machines and I’ve had my share of problems (mostly due to ignorance) but I’ve never encountered corruption. Mostly I just run out of disk space because I forgot to balance or the disk itself had an issue and I lost whatever it was that was stored in those blocks.
I’ve had to repair a btrfs partition before due to who-knows-what back when it was new but it’s been over a decade since I’ve had an issue like that. I remember
btrfs check --repairbeing totally useless back then haha. My memory on that event is fuzzy but I think I fixed whatever it was bitching about by remounting the filesystem with an extra option that forced it to recreate a cache of some sort. It ran for many years after that until the disk spun itself into oblivion.Anecdotal but btrfs ate my data 2 or 3 times in the early days. I have used zfs since and don’t worry about my filesystem fucking things up.



















