
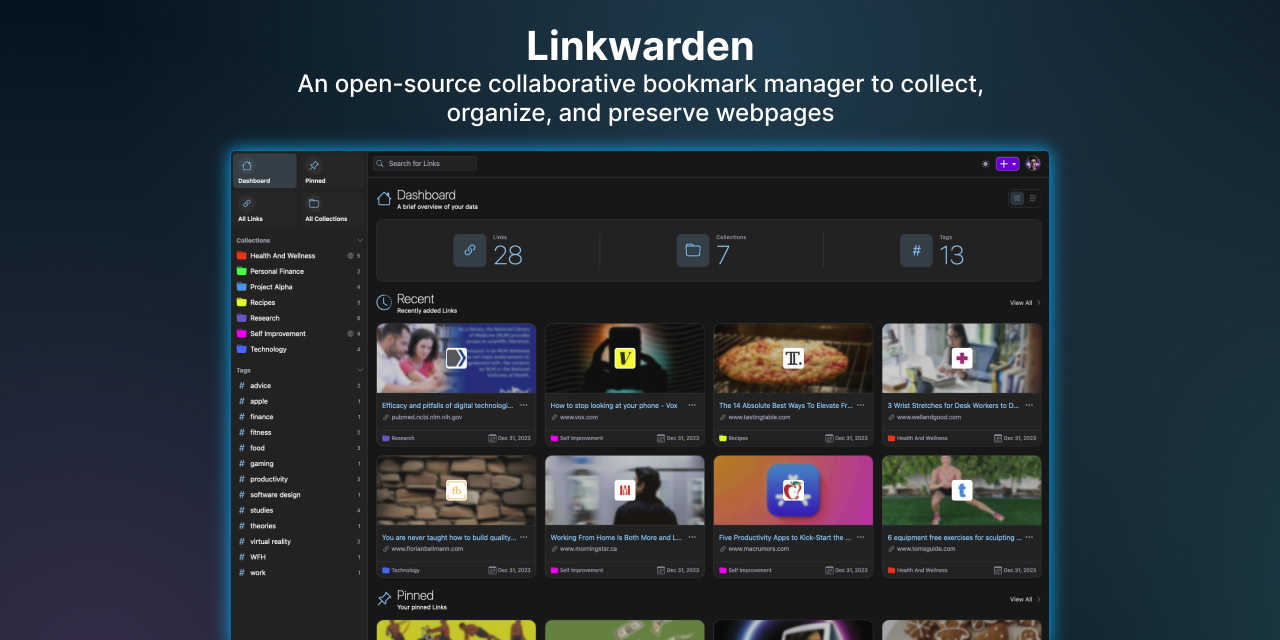
Greetings everyone! Daniel here, I’ve been working on Linkwarden part-time over the past few months.
Linkwarden is a self-hosted, open-source collaborative bookmark manager to collect, organize and archive webpages.
Key features:
- 📸 Preserve webpages as Screenshot, PDF, etc. So you can access them even if they are taken down.
- 👥 Collaborative, so you can share your collections with your friends and colleagues. You can also make them public and share them with the world.
- 📱 Designed for every screen size, from widescreen monitors down to smartphones.
- ⚡️ Open source and fully self-hostable!
- ✨ And so many more features! (Literally, just didn’t want to make this post too long. Check out the Github repo and Website for more info…)
If you like what we’re doing, you can support the project by either starring ⭐️ the repo to make it more visible to others or by subscribing to the Cloud plan (which helps the project, a lot).
Things like mobile app are already on the project roadmap and I’m so excited to share them with you in the future.
Feedback is always welcome, so feel free to share your thoughts!
Website: https://linkwarden.app
Archivebox is in my obsidian workflow, it grabs every link in my vault and archives it. I didn’t see an API in linkwarden, perhaps I missed it.
Do you have any particular way of organizing the links themselves? I’ve moved to hosting all my bookmarks in Obsidian as well and am curious as to how others go about it
I treat links like atomic notes. I add as much detail as I feel like to each link, sometimes I go back and add tags and notes. Then I have an exceptionally poor process that attempts to go back to each link, get the archivebox archive and uses python to attempt to grab the article text (I tried using newspaper3k at first, but it’s unmaintained, so moved to readability). Then sticks the resulting link text into the note.
Honestly It’s a mess, and I really haven’t figured out how to do link things together very well, but, for now, it’s my little disaster of a solution.