In evidence for the suit against OpenAI, the plaintiffs claim ChatGPT violates copyright law by producing a “derivative” version of copyrighted work when prompted to summarize the source.
Both filings make a broader case against AI, claiming that by definition, the models are a risk to the Copyright Act because they are trained on huge datasets that contain potentially copyrighted information
They’ve got a point.
If you ask AI to summarize something, it needs to know what it’s summarizing. Reading other summaries might be legal, but then why not just read those summaries first?
If the AI “reads” the work first, then it would have needed to pay for it. And how do you deal with that? Is a chatbot treated like one user? Or does it need to pay for a copy for each human that asks for a summary?
I think if they’d have paid for a single ebbok Library subscription they’d be fine. However the article says they used pirate libraries so it could read anything on the fly.
Pointing an AI at pirated media is going to be hard to defend in court. And a class action full of authors and celebrities isn’t going to be a cakewalk. They’ve got a lot of money to fight, and have lots of contacts for copyright laws. I’m sure all the publishers are pissed too.
Everyone is going after AI money these days, this seems like the rare case where it’s justified
If the AI “reads” the work first, then it would have needed to pay for it
That’s not actually true. Copyright applies to distribution, not consumption. You violate no law when I create an unauthorized copy of a work, and you read that copy. Copyright law prohibits you from distributing further copies, but it does not prohibit you from possessing the copy I provided you, nor are you prohibited from speaking about the copy you have acquired.
Unless the AI is regurgitating substantial parts of the original work, it’s output is a “transformative derivation”, which is not subject to the protections of the original copyright. The AI is doing what English teachers ask of every school-age child: create a book report.
Copyright applies to distribution, not consumption. You violate no law when I create an unauthorized copy of a work
This is completely untrue. Making any unauthorised copy is an infringement of copyright. Hell, the UK determined that merely loading a pirated game into RAM was unauthorised copying, making the act of playing a pirated game unlawful - thankfully this is ruling only the case in the UK, however the basic principles of copyright are the same all over the world.
When you buy something, you get a limited license to make copies for the purpose of viewing the material. That license does not extend to making backup copies. However, in a practical sense, it is very unlikely you will be prosecuted for most kinds of infringement like this - particularly when no money is involved. It’s still infringement, though.
Edit: I will say though: you violate no law when you view a copy I create. However I would still be infringing for making and showing you the copy.
In the case of making a book report, that is educational, and thus fair use. ChatGPT is not educational - you might use it for education, but ChatGPT’s use of copyrighted material is for commercial enterprise.
The uploader is the person creating the copy. Downloading is not creating a copy; downloading is receiving a copy.
I would love to see a citation on that UK precedent, but as you said: “thankfully this is only the case in the UK” and does not apply in the rest of the world.
Making any unauthorised copy is an infringement of copyright.
The exceptions to that are so numerous that the statement is closer to false than truth. “Fair Use” blows the absolute nature of that statement out of the water.
There has never been a successful prosecution for downloading only.
Every single transfer of data is a copy. There is no such thing as moving data. Only copying it and then voluntarily deleting the original, to fake it having “moved”
I feel you guys are arguing very precise legal matters without defining the jurisdiction. I mean sure, go ahead, but it’s meaningless. One could say “I live in this random country and we don’t even have a concept of copyright, therefore it does not exist!”
eh it gets fuzzy. the sender transmits, but the receiver also writes a copy. it gets copied to the wire, and it gets copied from the wire. there is an ephemeral intermediate copy “on the wire”. I guess there’s no right answer; it’s like a fractal, the answer keeps changing when you look deeper
We’re not talking about fair use though - which also is incredibly limited. It only applies to education, news or criticism. Fair use would be an authorised copy, by definition.
and does not apply in the rest of the world.
The specific ruling does not apply to the rest of the world, so there is no established precedent elsewhere that playing a pirated video game is an offense. This just means someone wishing to prosecute this offense would have no case law to back up their claim. However the principle that led to the ruling is the same - you need a license to make a copy (except for fair use, which as I say would rarely apply) and computers copy files internally in order to display their content.
The uploader is the person creating the copy. Downloading is not creating a copy; downloading is receiving a copy.
One person is providing a copy to someone else - that person is infringing copyright - and the person receiving is writing a copy to their device, and furthermore needs to make copies to display the content - that person is also infringing copyright.
You can’t open a file like you would a book. You need to copy and process the file in order to display it.
There has never been a successful prosecution for downloading only.
There have been no prosecutions for downloading only because the level of damages is so low that it isn’t worth the cost of going to court. That doesn’t make it less illegal, it’s just more likely you’ll get away with it.
There was still copyright infringement because the company probably downloaded the text (which created another copy) and modified it (alteration is also protected by copyright) before using it as training data. If you write an original novel and admit that you had pirated a bunch of novels to use for reference, those novels were still downloaded illegally even if you’ve deleted them by now. The AI isn’t copyright infringement itself, it’s proof that copyright infringement has happened.
But personally I don’t think the actual laws will matter so much as which side has the better case for why they will lead to more innovation and growth for the economy.
There was still copyright infringement because the company probably downloaded the text (which created another copy)
Sure, someone likely infringed on copyright for that copy to be created, but the person/entity committing that infringement is the sender, not the receiver. The uploader is the infringing party, not the downloader.
If you write an original novel and admit that you had pirated a bunch of novels to use for reference, those novels were still downloaded illegally even if you’ve deleted them by now.
They were uploaded illegally. The people who distributed those copies to me have infringed on copyright, sure. My receiving those copies does not constitute infringement. Uploading is the illegal act, not downloading.
My work does not violate copyright, unless I use a substantial part of the other works. But, if I used substantial parts of those works, my work would be some sort of “derivation” and not the “original novel” you declared it. (Many types of derivation fall within “fair use” and do not constitute infringement.)
Whether I delete the works or not is entirely irrelevant. I am prohibited from creating and distributing additional copies, but I am not prohibited from receiving, possessing, or consuming an unauthorized copy.
The uploader is the infringing party, not the downloader.
an exclusive right of the copyright holder is the right to duplicate their work. downloading IS illegal because you’re creating an unauthorized duplicate of the work on your machine. your duplicate is distinct from the duplicate that someone else had created and uploaded. it’s just very hard to get caught downloading, and it’s not very cost effective for companies to pursue since they would only stop one person. that’s why most companies like the RIAA targeted torrents for their lawsuits, because they could easily see the ip addresses (which is why you should always use a vpn when torrenting) and because they could shut down uploaders. but downloading itself is still very illegal
My work does not violate copyright, unless I use a substantial part of the other works.
like I said, the AI is not a violation (probably, unless the courts later disagree), it’s proof that unauthorized duplication of copyrighted works has occurred, and that is illegal
You cannot create a copy of a work that you do not possess. The downloader does not possess the work to create a copy. Only the uploader is even capable of creating the copy. The downloader cannot create a copy; he can only request.
If he does something else with that copy he receives, he becomes something other than merely a downloader. That “something else” could be unlawful, but that “something else” is not “downloading”.
It could be unlawful if the downloader gains unauthorized access to the computer system, but that would not be a copyright violation. It could be unlawful if the downloader conspires with the uploader, but the degree of collaboration would have to be much greater to support a conspiracy charge.
Downloading does not meet the statutory criteria for copyright infringement. Downloading alone is not infringement.
Exactly: seeding is uploading, and uploading can be infringement. So, if your torrent client seeded any part of the work to anyone, that could be considered infringement.
But, there is no evidence that ChatGPT received the works in question via torrent, and even if there was, there is no evidence that they actually seeded anything back to the swarm. Hell, there’s no evidence that ChatGPT even actually possesses the works in question.
Can the sources where ChatGPT got it’s information from be traced? What if it got the information from other summaries?
I think the hardest thing for these companies will be validating the information their AI is using. I can see an encyclopedia-like industry popping up over the next couple years.
Btw I know very little about this topic but I find it fascinating
Yes! They publish the data sources and where they got everything from. Diffusers (stable diffusion/midjoirny etc) and GPT both use tons of data that was taken in ways that likely violate that data’s usage agreement.
Imo they deserve whatever lawsuits they have coming.
It doesn’t seem to be too common for books to include specific clauses or EULAs that prohibit their use as data in machine learning systems. I’m curious if there are really any aspects that cover this without it being explicitly mentioned. I guess we’ll find out.
It depends on if the summary is an infringing derivative work, doesn’t it? Wikipedia is full of summaries, for example, and it’s not violating copyright.
If they illegally downloaded the works, that feels like a standalone issue to me, not having anything to do with AI.
A book review published in a newspaper is a commercial venture for the purpose of selling ads. The commercial aspect doesn’t make the review an infringement.
A summary is a “Transformative Derivation”. It is a related work, created for a fundamentally different purpose. It is a discussion about the work, not a copy of the work. Transformative derivations are not infringements, even where they are specifically intended to be used for commercial purposes.
A book review is most likely critical, and thus falls under fair use.
A summary is not critical, so would not have a fair use exemption. I would also disagree that it is transformative. That argument is about work that is so different to the original that it must be considered a separate piece (eg new music that uses a sample from old music). A summary is inherently not transformative, because it is merely a shortened version of the original - the ideas expressed are the same.
Transformative doesn’t mean that the idea is different. It means the purpose for expressing the idea is different. Informing an individual or the general public of the general idea presented in a book is not an infringement. If it were, every book report every student is ever asked to write would be an infringement.
Transformativeness is a characteristic of such derivative works that makes them transcend, or place in a new light, the underlying works on which they are based.
A summary would not place the original work in a new light. A summary is the same work but shorter. A summary would be infringement.
Student book reports are for educational purposes, which has its own specific exemption under fair use. As does work which is critical of the original, along with news. A critical piece, for example, is transformative because it introduces new ideas, talking about the work and framing it in new ways.
AI meets none of these exemptions with a summary. It’s debatable whether it even could meet these exemptions in the way that it functions.
Student book reports are for educational purposes, which has its own specific exemption under fair use. As does work which is critical of the original, along with news. A critical piece, for example, is transformative because it introduces new ideas, talking about the work and framing it in new ways.
You’re forgetting two other important categories of fair use. Paste that student’s book report in a newspaper, and it is no longer “educational”, but it is still “news reporting”. “Author publishes work” is a newsworthy event.
Paste it in response to an individual asking about the work, and again, it is no longer educational, but it is still “commentary”, which is much the same as news reporting but with a typically smaller audience.
Even if these two categories of fair use were not specifically included in copyright law, they would naturally arises from the right to free speech. Making a summary subject to the original copyright would make it unlawful for anyone to even discuss the work at all.



They’ve got a point.
If you ask AI to summarize something, it needs to know what it’s summarizing. Reading other summaries might be legal, but then why not just read those summaries first?
If the AI “reads” the work first, then it would have needed to pay for it. And how do you deal with that? Is a chatbot treated like one user? Or does it need to pay for a copy for each human that asks for a summary?
I think if they’d have paid for a single ebbok Library subscription they’d be fine. However the article says they used pirate libraries so it could read anything on the fly.
Pointing an AI at pirated media is going to be hard to defend in court. And a class action full of authors and celebrities isn’t going to be a cakewalk. They’ve got a lot of money to fight, and have lots of contacts for copyright laws. I’m sure all the publishers are pissed too.
Everyone is going after AI money these days, this seems like the rare case where it’s justified
That’s not actually true. Copyright applies to distribution, not consumption. You violate no law when I create an unauthorized copy of a work, and you read that copy. Copyright law prohibits you from distributing further copies, but it does not prohibit you from possessing the copy I provided you, nor are you prohibited from speaking about the copy you have acquired.
Unless the AI is regurgitating substantial parts of the original work, it’s output is a “transformative derivation”, which is not subject to the protections of the original copyright. The AI is doing what English teachers ask of every school-age child: create a book report.
This is completely untrue. Making any unauthorised copy is an infringement of copyright. Hell, the UK determined that merely loading a pirated game into RAM was unauthorised copying, making the act of playing a pirated game unlawful - thankfully this is ruling only the case in the UK, however the basic principles of copyright are the same all over the world.
When you buy something, you get a limited license to make copies for the purpose of viewing the material. That license does not extend to making backup copies. However, in a practical sense, it is very unlikely you will be prosecuted for most kinds of infringement like this - particularly when no money is involved. It’s still infringement, though.
Edit: I will say though: you violate no law when you view a copy I create. However I would still be infringing for making and showing you the copy.
In the case of making a book report, that is educational, and thus fair use. ChatGPT is not educational - you might use it for education, but ChatGPT’s use of copyrighted material is for commercial enterprise.
The uploader is the person creating the copy. Downloading is not creating a copy; downloading is receiving a copy.
I would love to see a citation on that UK precedent, but as you said: “thankfully this is only the case in the UK” and does not apply in the rest of the world.
The exceptions to that are so numerous that the statement is closer to false than truth. “Fair Use” blows the absolute nature of that statement out of the water.
There has never been a successful prosecution for downloading only.
Every single transfer of data is a copy. There is no such thing as moving data. Only copying it and then voluntarily deleting the original, to fake it having “moved”
Every single transmission of data is a copy. Receiving data is not. The person creating the copy is the sender, not the receiver.
I feel you guys are arguing very precise legal matters without defining the jurisdiction. I mean sure, go ahead, but it’s meaningless. One could say “I live in this random country and we don’t even have a concept of copyright, therefore it does not exist!”
Sarah Silverman is an American actress. OpenAI is an American country. Relevant jurisdiction was defined in the headline.
eh it gets fuzzy. the sender transmits, but the receiver also writes a copy. it gets copied to the wire, and it gets copied from the wire. there is an ephemeral intermediate copy “on the wire”. I guess there’s no right answer; it’s like a fractal, the answer keeps changing when you look deeper
We’re not talking about fair use though - which also is incredibly limited. It only applies to education, news or criticism. Fair use would be an authorised copy, by definition.
The specific ruling does not apply to the rest of the world, so there is no established precedent elsewhere that playing a pirated video game is an offense. This just means someone wishing to prosecute this offense would have no case law to back up their claim. However the principle that led to the ruling is the same - you need a license to make a copy (except for fair use, which as I say would rarely apply) and computers copy files internally in order to display their content.
One person is providing a copy to someone else - that person is infringing copyright - and the person receiving is writing a copy to their device, and furthermore needs to make copies to display the content - that person is also infringing copyright.
You can’t open a file like you would a book. You need to copy and process the file in order to display it.
There have been no prosecutions for downloading only because the level of damages is so low that it isn’t worth the cost of going to court. That doesn’t make it less illegal, it’s just more likely you’ll get away with it.
There was still copyright infringement because the company probably downloaded the text (which created another copy) and modified it (alteration is also protected by copyright) before using it as training data. If you write an original novel and admit that you had pirated a bunch of novels to use for reference, those novels were still downloaded illegally even if you’ve deleted them by now. The AI isn’t copyright infringement itself, it’s proof that copyright infringement has happened.
But personally I don’t think the actual laws will matter so much as which side has the better case for why they will lead to more innovation and growth for the economy.
Sure, someone likely infringed on copyright for that copy to be created, but the person/entity committing that infringement is the sender, not the receiver. The uploader is the infringing party, not the downloader.
They were uploaded illegally. The people who distributed those copies to me have infringed on copyright, sure. My receiving those copies does not constitute infringement. Uploading is the illegal act, not downloading.
My work does not violate copyright, unless I use a substantial part of the other works. But, if I used substantial parts of those works, my work would be some sort of “derivation” and not the “original novel” you declared it. (Many types of derivation fall within “fair use” and do not constitute infringement.)
Whether I delete the works or not is entirely irrelevant. I am prohibited from creating and distributing additional copies, but I am not prohibited from receiving, possessing, or consuming an unauthorized copy.
an exclusive right of the copyright holder is the right to duplicate their work. downloading IS illegal because you’re creating an unauthorized duplicate of the work on your machine. your duplicate is distinct from the duplicate that someone else had created and uploaded. it’s just very hard to get caught downloading, and it’s not very cost effective for companies to pursue since they would only stop one person. that’s why most companies like the RIAA targeted torrents for their lawsuits, because they could easily see the ip addresses (which is why you should always use a vpn when torrenting) and because they could shut down uploaders. but downloading itself is still very illegal
like I said, the AI is not a violation (probably, unless the courts later disagree), it’s proof that unauthorized duplication of copyrighted works has occurred, and that is illegal
You cannot create a copy of a work that you do not possess. The downloader does not possess the work to create a copy. Only the uploader is even capable of creating the copy. The downloader cannot create a copy; he can only request.
If he does something else with that copy he receives, he becomes something other than merely a downloader. That “something else” could be unlawful, but that “something else” is not “downloading”.
It could be unlawful if the downloader gains unauthorized access to the computer system, but that would not be a copyright violation. It could be unlawful if the downloader conspires with the uploader, but the degree of collaboration would have to be much greater to support a conspiracy charge.
Downloading does not meet the statutory criteria for copyright infringement. Downloading alone is not infringement.
US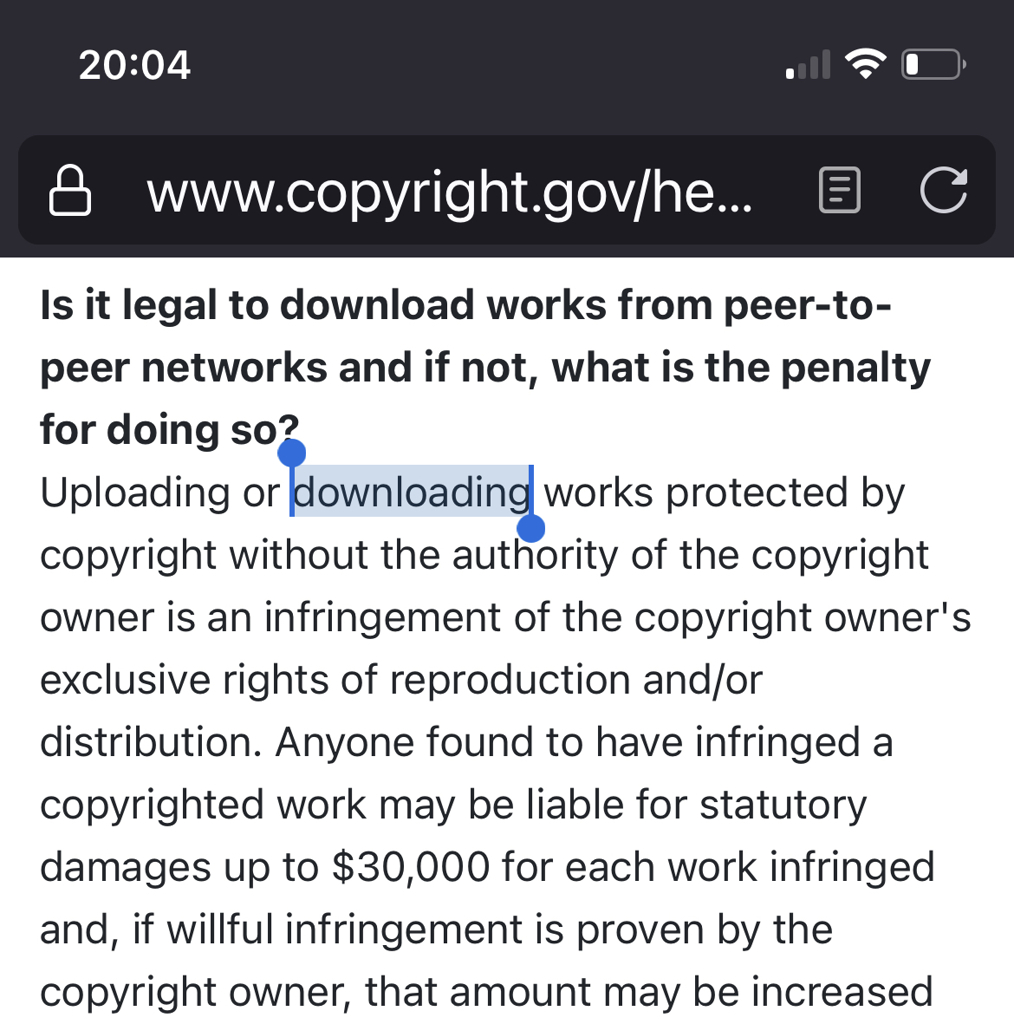
UK
EU
Australia cuz why the hell not
The “You wouldn’t steal a car” anti-piracy ad is coming to mind lol
They get people torrenting movies by saying you seed while you leach…
So if they torrented them in mass, they broke it.
Exactly: seeding is uploading, and uploading can be infringement. So, if your torrent client seeded any part of the work to anyone, that could be considered infringement.
But, there is no evidence that ChatGPT received the works in question via torrent, and even if there was, there is no evidence that they actually seeded anything back to the swarm. Hell, there’s no evidence that ChatGPT even actually possesses the works in question.
“It was like this when I got it”
Can the sources where ChatGPT got it’s information from be traced? What if it got the information from other summaries?
I think the hardest thing for these companies will be validating the information their AI is using. I can see an encyclopedia-like industry popping up over the next couple years.
Btw I know very little about this topic but I find it fascinating
Yes! They publish the data sources and where they got everything from. Diffusers (stable diffusion/midjoirny etc) and GPT both use tons of data that was taken in ways that likely violate that data’s usage agreement.
Imo they deserve whatever lawsuits they have coming.
It doesn’t seem to be too common for books to include specific clauses or EULAs that prohibit their use as data in machine learning systems. I’m curious if there are really any aspects that cover this without it being explicitly mentioned. I guess we’ll find out.
I think with a book your standard digital license / copyright would forbid it, would it not?
Maybe. I’m interested in the specifics.
It depends on if the summary is an infringing derivative work, doesn’t it? Wikipedia is full of summaries, for example, and it’s not violating copyright.
If they illegally downloaded the works, that feels like a standalone issue to me, not having anything to do with AI.
Wikipedia is a non profit whose primary purpose is education. ChatGPT is a business venture.
A book review published in a newspaper is a commercial venture for the purpose of selling ads. The commercial aspect doesn’t make the review an infringement.
A summary is a “Transformative Derivation”. It is a related work, created for a fundamentally different purpose. It is a discussion about the work, not a copy of the work. Transformative derivations are not infringements, even where they are specifically intended to be used for commercial purposes.
A book review is most likely critical, and thus falls under fair use.
A summary is not critical, so would not have a fair use exemption. I would also disagree that it is transformative. That argument is about work that is so different to the original that it must be considered a separate piece (eg new music that uses a sample from old music). A summary is inherently not transformative, because it is merely a shortened version of the original - the ideas expressed are the same.
Transformative doesn’t mean that the idea is different. It means the purpose for expressing the idea is different. Informing an individual or the general public of the general idea presented in a book is not an infringement. If it were, every book report every student is ever asked to write would be an infringement.
https://en.m.wikipedia.org/wiki/Transformative_use
A summary would not place the original work in a new light. A summary is the same work but shorter. A summary would be infringement.
Student book reports are for educational purposes, which has its own specific exemption under fair use. As does work which is critical of the original, along with news. A critical piece, for example, is transformative because it introduces new ideas, talking about the work and framing it in new ways.
AI meets none of these exemptions with a summary. It’s debatable whether it even could meet these exemptions in the way that it functions.
You’re forgetting two other important categories of fair use. Paste that student’s book report in a newspaper, and it is no longer “educational”, but it is still “news reporting”. “Author publishes work” is a newsworthy event.
Paste it in response to an individual asking about the work, and again, it is no longer educational, but it is still “commentary”, which is much the same as news reporting but with a typically smaller audience.
Even if these two categories of fair use were not specifically included in copyright law, they would naturally arises from the right to free speech. Making a summary subject to the original copyright would make it unlawful for anyone to even discuss the work at all.
You’re really stretching to try and make your arguments seem correct.